
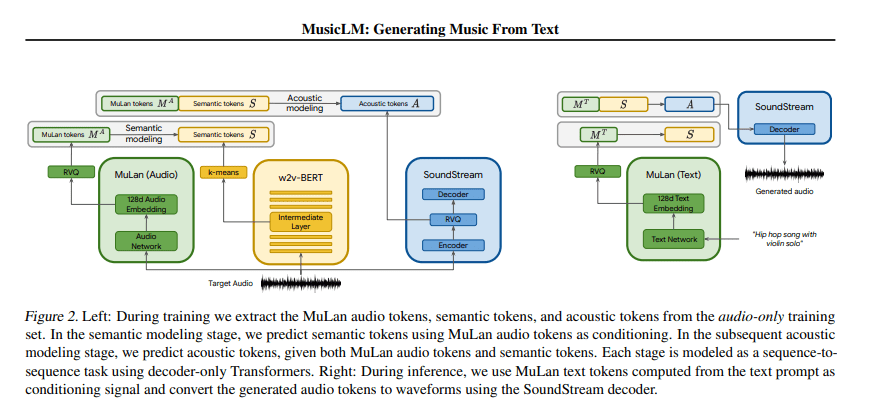
MusicLM es un modelo que genera música de alta fidelidad a partir de descripciones de texto, por ejemplo «una melodía relajante de violín respaldada por un riff de guitarra distorsionado». MusicLM proyecta el proceso de generación de música condicional como una tarea de modelado jerárquico de secuencia a secuencia, y genera música a 24 kHz que se mantiene constante durante varios minutos.
Los autores son Andrea Agostinelli, Timo I. Denk, Zalán Borsos, Jesse Engel, Mauro Verzetti, Antoine Caillon, Qingqing Huang, Aren Jansen, Adam Roberts, Marco Tagliasacchi, Matt Sharifi, Neil Zeghidour, Christian Frank, del equipo de Google Research.
Los experimentos realizados por los autores muestran que MusicLM supera a los sistemas anteriores tanto en calidad de audio como en adherencia a la descripción del texto. Además, demuestran que MusicLM se puede condicionar tanto en texto como en melodía, ya que puede transformar melodías silbadas y tarareadas de acuerdo con el estilo descrito en una leyenda de texto.
Para respaldar futuras investigaciones, publicaron MusicCaps, un conjunto de datos compuesto por 5.500 pares de música y texto, con descripciones de texto enriquecido proporcionadas por expertos humanos.
